
Introduction
Feature engineering is a cornerstone of data science, playing a crucial role in enhancing the performance of machine learning models. It involves the process of transforming raw data into a format that can be effectively utilized by algorithms, leading to improved model accuracy and robustness. In this article, we will delve into various strategies for feature engineering, covering essential concepts such as feature extraction, data transformation, feature selection, and understanding feature importance.

Feature Engineering Overview
Feature engineering encompasses a broad spectrum of techniques aimed at maximizing the predictive power of machine learning models. The primary goal is to create new features or modify existing ones to provide more meaningful insights to the algorithms.
Feature Extraction
Feature extraction involves deriving new
features from the existing dataset, often by
condensing the information into a more
relevant and concise form. Techniques like
Principal Component Analysis (PCA), tDistributed Stochastic Neighbor Embedding
(t-SNE), and word embeddings in natural language processing are common examples of feature extraction.

Data Transformation

Data transformation is the process of converting raw data into a suitable format for machine learning models. This includes handling missing values, scaling features, and encoding categorical variables. Standardization and normalization are essential techniques in data transformation, ensuring that all features contribute equally to the model’s performance.
Feature Selection
Feature selection is the process of identifying and using only the most relevant features for model training, discarding irrelevant or redundant ones. This not only reduces computational complexity but also enhances model interpretability.

Techniques like Recursive Feature Elimination (RFE), LASSO regression, and tree-based methods are widely employed for feature selection.
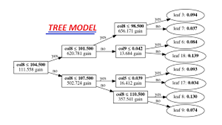
Feature Importance
Understanding feature importance is crucial for interpreting the model’s behavior and identifying the most influential features. Algorithms like decision trees and ensemble methods provide a natural way to assess feature importance. Visualizations, such as permutation importance and SHAP (SHapley Additive exPlanations), offer insightful ways to interpret and communicate feature importance.
Conclusion

Feature engineering is a dynamic and iterative process, demanding a deep understanding of both the dataset and the underlying machine learning algorithms. By employing effective strategies such as feature extraction, data transformation, feature selection, and assessing feature importance, data scientists can significantly
enhance the performance and interpretability of their models. In the ever-evolving field of data science, mastering feature engineering is a key step towards building robust and accurate machine learning models


