
Introduction:
In the ever-evolving realm of data science, achieving optimal model performance is a perpetual quest. One crucial concept that plays a pivotal role in this journey is the bias-variance tradeoff. Mastering this delicate equilibrium between bias and variance is essential for creating models that not only fit the training data well but also generalize effectively to unseen data.
In this blog, we’ll delve into the intricacies of the bias-variance tradeoff, exploring its connection to model performance, overfitting, underfitting, and the overarching goal of achieving robust generalization.
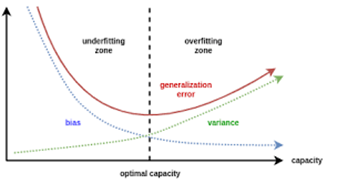
Understanding Bias and Variance:
Before we explore the tradeoff, let’s unravel the fundamental concepts of bias and variance.
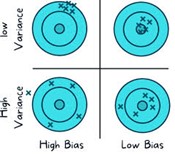
Bias:
- Bias represents the error introduced by approximating a real-world problem with a simplified model.
- High bias models tend to be too simplistic, making assumptions that may not align with the underlying data distribution.
- Commonly associated with underfitting, high bias can result in poor performance on both training and unseen data.
Variance:
- Variance, on the other hand, measures the model’s sensitivity to small fluctuations in the training data.
- High variance models capture noise in the training data and may not generalize well to new, unseen data.
- This phenomenon is often linked with overfitting, where the model performs exceptionally well on the training data but fails to generalize to new instances.
The Tradeoff:
The bias-variance tradeoff is a delicate balancing act between these two opposing forces. Striking the right balance is crucial for creating models that generalize well while avoiding the pitfalls of underfitting and overfitting.
Underfitting (High Bias):
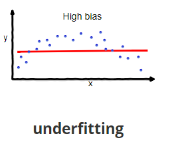
Models that underfit fail to capture the underlying patterns in the data.The simplicity of the model restricts its ability to adapt to the complexity of the true data distribution.As a result, underfit models perform poorly on both the training set and unseen data.
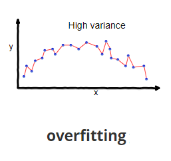
Overfitting (High Variance):
Overfit models excel in fitting the training data but do so too closely, capturing noise and outliers.This tight coupling with the training data leads to poor generalization on new, unseen instances.High variance models often suffer from a lack of robustness and may not perform well in real-world scenarios.
Achieving Generalization:
The goal of any model is to generalize well to new, unseen data. Balancing bias and variance involve finding the sweet spot that minimizes both training and test errors. Here are some strategies to achieve this:
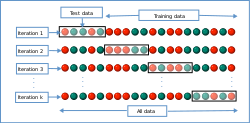
- Cross-validation:
Employ cross-validation techniques to assess model performance on different subsets of the data.This helps in identifying whether the model is underfitting or overfitting and guides adjustments accordingly.
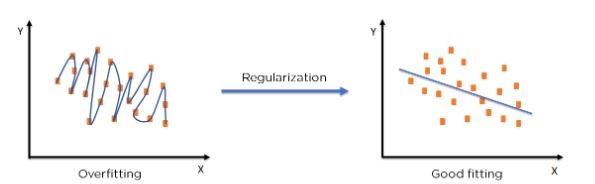
- Regularization:
- Integrate regularization techniques, such as L1 or L2 regularization, to penalize overly complex models.
- This helps control the growth of model parameters and mitigates the risk of overfitting.
- Feature Engineering:
- Carefully select and engineer features to enhance the model’s ability to discern relevant patterns.
- Feature selection and transformation can contribute to reducing both bias and variance.
Conclusion:
In the dynamic landscape of data science, understanding the bias-variance tradeoff is paramount for crafting models that strike the right balance between simplicity and complexity. By navigating this tradeoff effectively, data scientists can enhance model performance, foster generalization, and contribute to the advancement of predictive analytics. The journey towards mastering the bias-variance tradeoff is an ongoing process, requiring continuous refinement and adaptation to the nuances of diverse datasets.


